

Site Reliability Engineering (SRE) has emerged as a pivotal discipline in the world of technology, ensuring that complex systems deliver their intended service levels. Originating from Google in the early 2000s, SRE has evolved into a fundamental practice for companies that demand high reliability from their software systems. This article aims to demystify the core principles of SRE, providing a practical guide for beginners to understand and integrate these practices into their daily operations.
Understanding the SRE Philosophy
What is SRE?
SRE is a set of practices and philosophies that aims to ensure that continuously delivered services run smoothly and reliably. It combines aspects of software engineering and applies them to infrastructure and operations problems, with a focus on automation and scalability.
Core Philosophy
The core philosophy of SRE is treating “operations” as if it were a software problem. The goal is to create scalable and highly reliable software systems. SRE is based on the premise that the most effective way to make systems scalable and reliable is through code.
How SRE Differs from Traditional IT
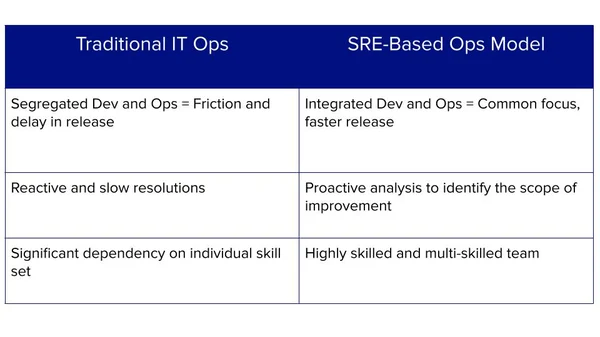
Unlike traditional IT operations, which often involve manual processes and reactive management, SRE emphasizes proactive measures and automation to prevent issues before they impact users. It is a shift from a solely operational focus to an integrated development and operational mindset.
The Five Pillars of SRE Explained
Pillar 1: Service Level Objectives (SLOs) and Service Level Indicators (SLIs)
SLOs and SLIs form the backbone of any SRE practice, providing clear, quantifiable metrics that guide the reliability of services. SLIs are precise measurements that reflect the health of the service from the user’s perspective, such as uptime, response time, and error rate. SLOs, on the other hand, are the targets set for SLI performance, defining the level of service reliability that the team aims to achieve. These goals must align with business objectives and user expectations, ensuring that technical teams focus their efforts on what truly matters to the business.
- Real-World Example: For a cloud storage provider, an SLI might be the availability of file retrieval operations, with an SLO stating that files should be retrievable within 300 milliseconds at least 99.95% of the time. By monitoring these indicators, SRE teams can prioritize maintenance and improvements, ensuring they meet or exceed these benchmarks.
Pillar 2: Error Budgets
Error budgets balance the need for rapid innovation against the necessity of maintaining a reliable service. An error budget is the maximum allowable threshold for service unreliability, quantitatively defined, which can be “spent” over a given period. This approach allows teams to make informed decisions about taking risks. If a service is performing well against its SLOs, teams might push more frequent updates or introduce new features. Conversely, breaching an error budget would mean focusing on improving stability before adding new service features.
- Strategic Use: An online retail platform uses its error budget to decide when to freeze new releases during peak shopping seasons, ensuring maximum stability when reliability is critical.
Pillar 3: Automation
Automation is essential in SRE to handle scale, manage complexity, and reduce manual toil. The goal is to automate routine operations and responses to standard incidents so that human operators can focus on more strategic tasks that require creative thinking. Effective automation also ensures that the service can recover quickly from failures without human intervention, improving mean time to recovery (MTTR) and overall service availability.
- Automation Example: Automating the rollout and rollback of new releases enables seamless updates and quick reversion if an update fails, minimizing user impact.
Pillar 4: Monitoring and Alerting
Monitoring systems collect data on the operational aspects of a service, providing real-time visibility into its health and performance. Effective monitoring is proactive, aiming to detect and address potential issues before they affect users. Alerting complements monitoring by notifying the team when a potential issue arises, based on predefined thresholds. However, not all alerts should lead to immediate action; they must be prioritized based on their potential impact on service quality and user experience.
- Best Practice: Implementing intelligent alerting systems that differentiate between critical issues and minor anomalies can prevent alert fatigue, ensuring that SRE teams focus on alerts that require immediate attention.
Pillar 5: Incident Response and Blameless Postmortems
Incident response is the procedure followed to address and resolve service disruptions as efficiently as possible. A key component of effective incident response is the conduct of blameless postmortems. These sessions are conducted after an incident is resolved and aim to uncover the root cause of the issue without assigning blame. This fosters a culture of transparency and continuous improvement, where learning from failures is prioritized over punitive measures.
- Incident Response Example: Following a service outage, the team gathers to analyze the incident, identifying that a recent code deployment inadvertently introduced a memory leak. The postmortem leads to improved review processes and monitoring alerts for similar future incidents.
Integrating SRE Principles into Daily Operations
For beginners, integrating SRE principles starts with understanding core concepts and gradually applying them to daily tasks. It involves:
- Cultivating a learning culture that encourages continual improvement.
- Using SRE tools and techniques to automate and improve reliability.
- Regular reviews of incidents and systems to ensure lessons are learned and applied.
SRE training for individuals and teams can significantly enhance their capability to build and maintain reliable systems. Site Reliability Engineering (SRE) Foundation Training provides both the theoretical underpinnings and practical skills necessary for implementing SRE practices effectively, thereby improving service reliability and operational efficiency.
Case Studies
1. Beginner’s Journey: Implementing SLOs and SLIs
A notable journey into SRE principles begins with Alice, a junior SRE at a mid-sized tech company specializing in online payment processing. Her first major task was to define and implement Service Level Indicators (SLIs) and Objectives (SLOs) for their core services. Starting with the customer transaction process, she identified key metrics such as transaction completion rate and response time.
Alice set an SLO that 99.9% of transactions should process successfully within two seconds. Initially, the team needed help to meet this target consistently. By using detailed monitoring and frequent analysis, Alice identified that peak times caused processing delays. Her solution involved optimizing database queries and implementing a more robust load-balancing strategy, which improved response times and stabilized the transaction success rate.
This experience was transformative for Alice and her team, as they learned the importance of setting realistic, measurable goals and the direct impact of SRE practices on customer satisfaction and business operations.
2. Successful Implementation: A Financial Services Firm
Consider the case of BetaBank, a financial services firm that faced frequent downtime issues, affecting customer trust and regulatory compliance. The firm decided to overhaul its IT approach by implementing SRE practices. The key challenge was the frequent outages caused by legacy systems that were not designed to handle the increased load of modern, digital banking services.
The SRE team at BetaBank began with a thorough assessment of existing SLIs and established new, stringent SLOs for their core services, such as fund transfers and account balance inquiries. They introduced robust monitoring systems and automated response mechanisms that could preemptively scale resources during high-demand periods and automatically reroute traffic during incidents.
Additionally, BetaBank implemented a rigorous incident response strategy. Every incident was followed by a blameless postmortem, leading to significant process adjustments. For instance, after one notable outage, the postmortem revealed that a specific service module failed under heavy load, which had not been anticipated. The team redesigned the service’s architecture to be more resilient and added fallback mechanisms.
Over a year, BetaBank noticed a 60% reduction in downtime. Customer satisfaction scores improved dramatically, as did the team’s ability to deploy new features without disrupting service. This case study demonstrates how adopting SRE principles can turn systemic reliability problems into opportunities for innovation and improvement.
Lessons Learned and Key Takeaways
Both case studies illustrate the importance of adopting a structured approach to reliability through SRE principles. Beginners like Alice quickly learned that detailed metrics (SLIs and SLOs) are vital for setting expectations and measuring outcomes. Established organizations like BetaBank show that a comprehensive adoption of SRE can transform service delivery, reducing downtime and improving customer experience.
In each case, the integration of monitoring, alerting, and automation proved critical in addressing and preempting issues. Furthermore, the practice of conducting blameless postmortems cultivated a culture where learning and improvement were prioritized over fault-finding.
Conclusion
Embracing the 5 pillars of SRE can transform how teams manage and operate their services. For beginners, the journey involves learning the philosophy, adopting the tools, and applying the practices. As they progress, they can see tangible improvements in service reliability and team efficiency.
Appendix
Further Reading: “Site Reliability Engineering” by Niall Richard Murphy and Betsy Beyer.
Glossary: Definitions of key terms like SLI, SLO, Error Budget, Toil, etc.