
Site Reliability Engineering (SRE) is a discipline that bridges the gap between software development and operations, applying a software engineering mindset to system administration topics. Developed by Google, SRE has become a cornerstone for organizations seeking to maintain the reliability, scalability, and performance of their systems. This blog explores the core principles of SRE, providing insights into how these principles can be leveraged to enhance IT infrastructure and drive business success.
What is Site Reliability Engineering (SRE)?
Site Reliability Engineering is a practice that applies aspects of software engineering to infrastructure and operations problems. The goal is to create scalable and highly reliable software systems. SRE originated at Google in the early 2000s as a means to manage large-scale systems efficiently and has since gained popularity across the IT industry.
SRE aims to balance the dual goals of ensuring system reliability while enabling rapid software development and deployment. This is achieved by implementing automation, continuous monitoring, and rigorous incident management processes.
Key Principles of Site Reliability Engineering
SRE is built on several core principles that guide its practices and objectives. Understanding these principles is crucial for organizations looking to implement or improve their SRE practices.
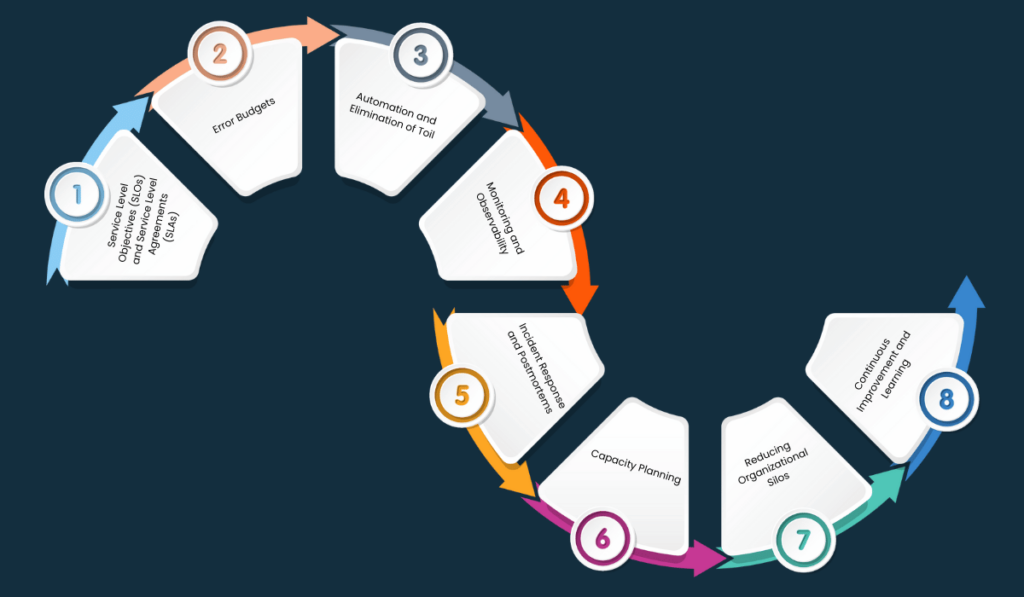
1. Service Level Objectives (SLOs) and Service Level Agreements (SLAs)
Service Level Objectives (SLOs) are specific measurable characteristics of a service, such as availability, latency, or throughput. SLOs are a critical part of SRE because they define the level of reliability that users can expect from a service. These objectives are typically negotiated between the SRE team and stakeholders to ensure that they align with business goals.
Service Level Agreements (SLAs), on the other hand, are formal agreements that often include SLOs and outline the penalties or compensations if those objectives are not met. SLAs are usually customer-facing and enforceable, making it crucial for SRE teams to maintain or exceed these standards.
2. Error Budgets
An error budget is the maximum amount of allowable failure or downtime for a service within a specified period. This concept is tightly coupled with SLOs and serves as a buffer between reliability and innovation. The error budget encourages a healthy balance between releasing new features and maintaining system stability.
When an error budget is exhausted, the SRE team may focus more on improving system reliability before allowing further releases or changes. This principle ensures that both developers and operations teams work together towards a common goal.
3. Automation and Elimination of Toil
Toil refers to repetitive, manual work that is devoid of long-term value. One of the primary goals of SRE is to reduce or eliminate toil through automation. By automating tasks such as deployments, monitoring, and incident response, SRE teams can focus on more strategic activities that drive innovation and improvement.
Automation also helps in achieving consistency and reducing human error, which is crucial for maintaining system reliability. SRE teams constantly look for opportunities to automate repetitive tasks, freeing up time for more complex problem-solving.
4. Monitoring and Observability
Monitoring and observability are foundational aspects of SRE. Monitoring involves tracking key performance metrics, such as CPU usage, memory, and network latency, to ensure that systems are operating within acceptable parameters.
Observability goes a step further by enabling SRE teams to understand the internal state of a system based on its external outputs. This includes the use of logs, traces, and metrics to gain deep insights into how a system behaves under different conditions. Effective observability allows for quicker detection and resolution of issues, minimizing downtime and enhancing user experience.
5. Incident Response and Postmortems
Incident response is the process of managing and resolving service disruptions as quickly as possible. SRE teams are often the first responders to incidents, employing predefined playbooks and automated tools to mitigate issues.
After an incident is resolved, SRE teams conduct postmortems to analyze what went wrong, why it happened, and how it can be prevented in the future. The key principle here is blamelessness—postmortems focus on learning and improvement rather than assigning blame. This approach fosters a culture of continuous learning and helps in building more resilient systems.
6. Capacity Planning
Capacity planning involves ensuring that a system has the necessary resources to handle current and future loads. SRE teams use historical data, performance metrics, and predictive models to estimate resource needs and plan for scaling.
Effective capacity planning prevents resource shortages that could lead to system failures or performance degradation. It also helps in optimizing costs by ensuring that resources are neither over-provisioned nor under-utilized.
7. Reducing Organizational Silos
SRE promotes the breaking down of silos between development, operations, and other IT teams. This is achieved through a shared responsibility model where both developers and SRE teams are accountable for the reliability and performance of services.
By fostering collaboration and communication across teams, SRE helps in aligning goals and reducing friction. This cross-functional approach is essential for building a culture of reliability and continuous improvement.
8. Continuous Improvement and Learning
Continuous improvement is at the heart of SRE. This principle involves regularly reviewing processes, tools, and systems to identify areas for enhancement. SRE teams are encouraged to experiment with new technologies, methodologies, and practices to drive innovation and better outcomes.
Learning from past experiences, both successes and failures, is also crucial. SRE teams document their learnings and share them across the organization to foster a culture of knowledge sharing and continuous improvement.
Implementing SRE Principles in Your Organization
Implementing SRE principles requires a shift in mindset and culture within an organization. Here are some steps to get started:
- Assess Current Practices: Begin by evaluating your current operations and development practices. Identify areas where SRE principles can be applied, such as automation, monitoring, or incident management.
- Set Clear Objectives: Define SLOs that align with your business goals and customer expectations. Use these objectives to guide your SRE practices and decision-making processes.
- Invest in Tools and Training: Equip your teams with the necessary tools for automation, monitoring, and incident response. Provide training to ensure that all team members understand and can apply SRE principles effectively.
- Foster Collaboration: Encourage collaboration between development, operations, and SRE teams. Break down silos and create a shared responsibility model for service reliability.
- Focus on Continuous Improvement: Regularly review your SRE practices and seek opportunities for improvement. Embrace a culture of learning and experimentation to drive innovation and better outcomes.
The Benefits of Embracing SRE
Adopting SRE principles can lead to significant benefits for organizations, including:
- Improved Reliability: By focusing on reliability from the outset, SRE helps ensure that services meet user expectations and minimize downtime.
- Enhanced Efficiency: Automation and reduction of toil free up resources, allowing teams to focus on strategic initiatives that drive business growth.
- Faster Incident Resolution: With robust monitoring and incident response practices, SRE teams can quickly detect and resolve issues, minimizing impact on users.
- Scalability: SRE principles support scalable systems that can handle growing workloads without compromising performance or reliability.
- Cost Optimization: Effective capacity planning and automation help optimize resource usage, reducing operational costs while maintaining high service quality.
Conclusion
Understanding and implementing the core principles of Site Reliability Engineering can transform the way your organization manages and operates its IT infrastructure. By focusing on reliability, automation, collaboration, and continuous improvement, SRE provides a framework that not only enhances system performance but also drives business success. As the IT landscape continues to evolve, embracing SRE will be crucial for organizations seeking to stay competitive and deliver exceptional user experiences.