

1. Introduction to Site Reliability Engineering (SRE)
In the fast-paced world of modern IT, where downtime and disruptions can have significant financial and reputational impacts, maintaining reliable and scalable systems has become a top priority. Site Reliability Engineering (SRE) is a discipline that emerged to bridge the gap between software development and IT operations, ensuring systems are resilient, efficient, and scalable. But what exactly is SRE, and why is it crucial in today’s IT landscape?
1.1 What is SRE?
Site Reliability Engineering, commonly known as SRE, is a set of principles and practices that apply software engineering approaches to IT operations. The primary goal of SRE is to create scalable and highly reliable software systems. Unlike traditional IT operations that focus on manual tasks and reactive processes, SRE emphasizes automation, proactive problem-solving, and a deep understanding of both the application and its underlying infrastructure.
The concept of SRE was first developed at Google by Ben Treynor Sloss, who famously described it as “what happens when you ask a software engineer to design an operations team.” This unique approach involves integrating developers into operations teams to ensure that software is not only developed but also deployed and managed with reliability in mind. SREs (Site Reliability Engineers) use their coding skills to build tools and automation that reduce toil and improve the efficiency of IT operations.
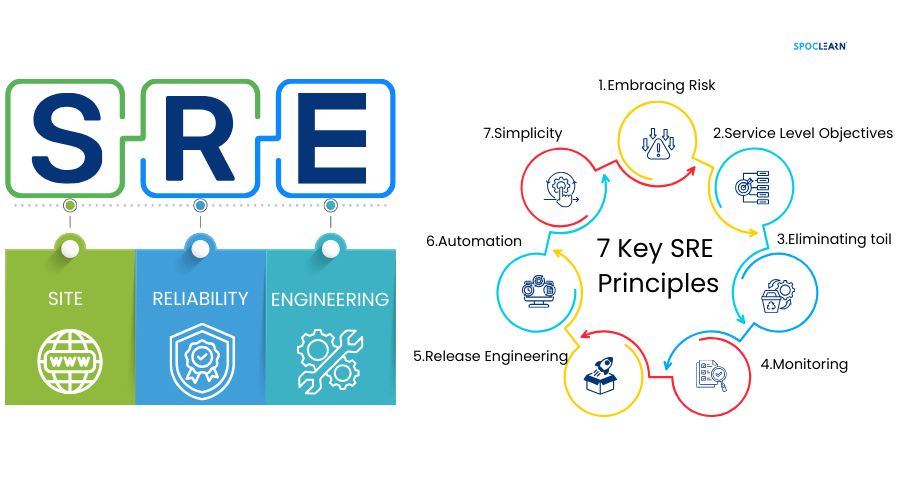
1.2 The Evolution of Site Reliability Engineering
The evolution of Site Reliability Engineering is rooted in the challenges of scaling operations in large, complex environments. In the early days of IT, operations were mostly manual, with system administrators responsible for managing servers, networks, and databases. As systems grew in complexity and scale, the limitations of this approach became apparent—manual processes were slow, error-prone, and difficult to scale.
The need for a new approach became more pressing as the demands on IT infrastructure grew. Companies like Google, with their massive, globally distributed systems, needed a way to ensure reliability at scale. This led to the birth of SRE, which introduced a new paradigm: treating operations as a software problem.
Over time, the principles of SRE have evolved and spread beyond Google, becoming a cornerstone of modern IT practices. Today, SRE is embraced by organizations of all sizes as a way to manage the complexity of modern systems and deliver reliable services to users.
1.3 The Importance of SRE in Modern IT
In today’s digital world, the importance of SRE cannot be overstated. As businesses become increasingly reliant on technology, the cost of downtime and service disruptions rises. SRE provides a structured approach to managing this risk by focusing on reliability, scalability, and efficiency.
One of the key benefits of SRE is its emphasis on automation. By automating routine tasks, SRE reduces the potential for human error and frees up engineers to focus on more strategic initiatives. This not only improves operational efficiency but also allows teams to innovate and deploy new features more rapidly.
Moreover, SRE’s proactive approach to problem-solving ensures that issues are identified and resolved before they impact users. By setting and monitoring service level objectives (SLOs), SRE teams can maintain a balance between reliability and agility, ensuring that systems are both stable and capable of evolving to meet new demands.
Site Reliability Engineering represents a fundamental shift in how we approach IT operations. By bringing together the best practices of software engineering and operations, SRE provides a framework for building systems that are reliable, scalable, and capable of supporting the demands of modern business. As IT environments continue to grow in complexity, the role of SRE will only become more critical in ensuring that technology remains a powerful enabler for business success.
2. Understanding the Core Principles of SRE
Site Reliability Engineering (SRE) is a discipline that brings together software engineering and IT operations to build and maintain scalable, reliable systems. To successfully implement SRE, it’s essential to understand its core principles, which serve as the foundation for all SRE practices. In this article, we’ll explore these principles, along with the critical roles of observability, monitoring, and essential metrics in driving SRE success.
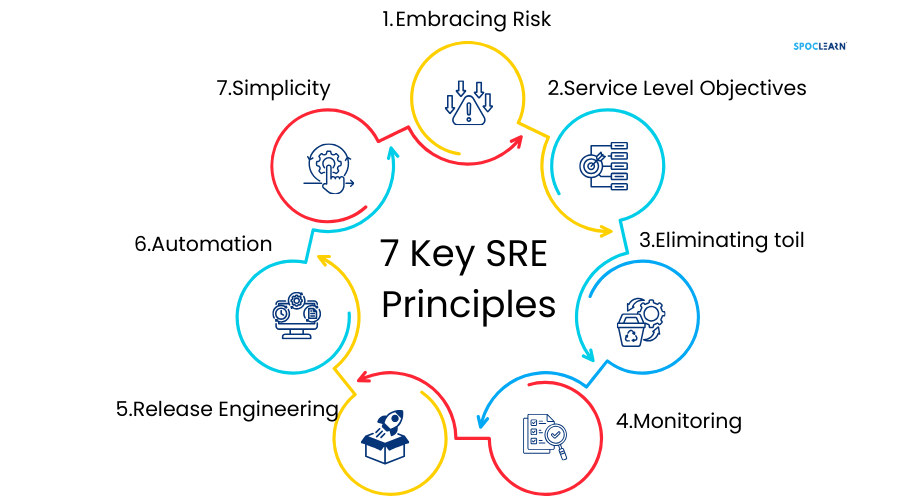
2.1 Key Principles in Site Reliability Engineering
At the heart of SRE are a few key principles that guide its practices and methodologies. The most fundamental principle is embracing risk. Unlike traditional IT operations, which aim to eliminate risk, SRE acknowledges that some level of risk is inevitable and must be managed rather than avoided. By setting clear service level objectives (SLOs) and error budgets, SRE teams can balance the need for innovation with the requirement for system reliability.
Another key principle is automation and reduction of toil. Toil refers to repetitive, manual work that doesn’t add long-term value but is necessary for system maintenance. SRE teams focus on automating these tasks to improve efficiency and allow engineers to focus on higher-value work, such as designing resilient systems.
Service Level Management is also a critical principle. SREs manage systems through service level indicators (SLIs), service level objectives (SLOs), and service level agreements (SLAs). These metrics help quantify the user experience and provide a framework for decision-making and prioritization.
2.2 The Role of Observability in SRE
Observability is a crucial aspect of SRE, enabling teams to understand and measure the internal state of a system based on its external outputs. It goes beyond simple monitoring by allowing engineers to ask questions and gain insights into the system’s behavior in real time.
The core components of observability include logs, metrics, and traces. Logs provide detailed records of events within the system, metrics offer numerical data on system performance, and traces show the path of a request through various services. Together, these components give SRE teams a comprehensive view of system health, helping them quickly diagnose and resolve issues.
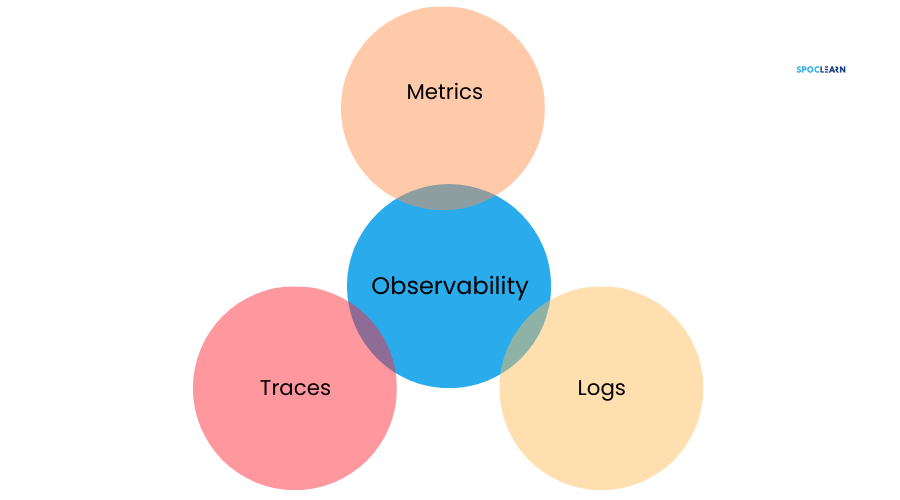
Observability also supports proactive problem-solving. By having a deep understanding of system behavior, SRE teams can anticipate potential failures and take preventive measures before users are affected. This capability is vital for maintaining reliability in complex, distributed systems.
2.3 The Role of Monitoring in SRE
While observability provides the ability to explore and understand system behavior, monitoring is about continuous measurement and alerting on predefined metrics. Monitoring focuses on detecting when the system deviates from expected behavior, such as breaches of SLOs, increased latency, or system outages.
Monitoring tools generate alerts that notify SRE teams of issues requiring immediate attention. These alerts are often tied to specific thresholds, such as a server reaching 90% CPU usage or a database query taking longer than expected. Effective monitoring ensures that potential problems are detected early, allowing teams to respond quickly and minimize downtime.
In SRE, monitoring is essential for maintaining a balance between system reliability and operational efficiency. It ensures that SRE teams have the information they need to keep services running smoothly while also allowing for rapid detection and resolution of issues.
2.4 Essential Metrics for SRE Success
Metrics are at the core of SRE practices, providing the data needed to make informed decisions and drive continuous improvement. The most critical metrics in SRE include Service Level Indicators (SLIs), Error Budgets, and Time to Recovery (TTR).
- Service Level Indicators (SLIs) are specific metrics that measure the performance and reliability of a service, such as uptime, latency, or error rate. These indicators help teams assess whether the system is meeting its SLOs.
- Error Budgets represent the allowable margin for system failures or downtime within a specified period. They help balance the need for innovation with the risk of system instability by defining how much unreliability is acceptable.
- Time to Recovery (TTR) measures the time it takes to restore a system to normal operation after an incident. A low TTR is essential for minimizing the impact of outages and maintaining user trust.
By focusing on these essential metrics, SRE teams can continuously improve system reliability, optimize performance, and ensure that their services meet user expectations.
In conclusion, understanding and applying the core principles of SRE—along with leveraging observability, monitoring, and essential metrics—are crucial for building and maintaining reliable systems in today’s dynamic IT environment. These practices ensure that SRE teams can proactively manage risks, automate away toil, and deliver services that meet the ever-increasing demands of users.
3. The Role of the Site Reliability Engineer
As businesses increasingly depend on technology, the role of Site Reliability Engineers (SREs) has become critical in ensuring that systems are both reliable and scalable. SREs bring a unique blend of software engineering and IT operations expertise to manage complex systems effectively. This article explores the role of SREs, their core responsibilities, what organizations expect from them, the qualities that make a great SRE, and whether SREs need to code.
3.1 What Do Site Reliability Engineers Do?
Site Reliability Engineers are responsible for ensuring that services are reliable, scalable, and performant. They work at the intersection of development and operations, applying engineering principles to solve operational challenges. Unlike traditional IT operations roles that focus primarily on system maintenance, SREs are proactive, using automation and software engineering to enhance system reliability and efficiency.
SREs are involved in the entire lifecycle of services—from design and implementation to deployment and maintenance. They collaborate closely with development teams to ensure that new features are built with reliability in mind, and they use their expertise to design systems that are resilient to failure.
3.2 Core Responsibilities of an SRE
The responsibilities of an SRE are varied and encompass a wide range of activities. Below is a table summarizing the core responsibilities of an SRE:
| Responsibility | Description |
|---|---|
| Incident Management | Responding to outages and incidents, quickly diagnosing issues, and restoring service. |
| Automation | Developing and implementing automation tools to reduce manual work and improve efficiency. |
| Monitoring and Alerting | Setting up monitoring systems and alerts to detect issues before they impact users. |
| Capacity Planning | Analyzing system usage and planning for future growth to ensure scalability. |
| Performance Optimization | Continuously improving system performance through optimization and tuning. |
| Service Level Management | Defining and managing Service Level Objectives (SLOs) and tracking Service Level Indicators (SLIs). |
| Security Compliance | Ensuring that systems comply with security policies and best practices. |
3.3 Expectations for SREs in an Organization
Organizations have high expectations for their SREs, given the critical nature of the role. SREs are expected to maintain high availability and reliability of services, often working in environments where downtime is unacceptable. They must be capable of handling incidents calmly and efficiently, often under pressure, to minimize the impact on users.
Additionally, SREs are expected to drive continuous improvement by identifying areas where systems can be made more reliable or efficient. This includes advocating for and implementing automation, reducing toil, and collaborating with development teams to build more resilient systems.
SREs are also expected to be proactive in their approach, identifying potential issues before they become critical and addressing them through preemptive action. This forward-thinking approach is essential for maintaining the stability of complex systems.
3.4 What Makes a Great Site Reliability Engineer?
A great Site Reliability Engineer possesses a unique combination of skills and attributes that enable them to excel in their role. Technical proficiency is a given—SREs must have a strong understanding of both software development and IT operations. However, what truly sets a great SRE apart is their problem-solving ability, adaptability, and communication skills.
Great SREs are adept at diagnosing complex issues, often under time constraints, and finding effective solutions quickly. They are adaptable, able to work across different environments and technologies, and they thrive in high-pressure situations. Communication is also key; SREs must be able to convey complex technical information clearly and collaborate effectively with diverse teams.
3.5 Can SREs Code?
Yes, SREs can and often do code. In fact, coding is a significant part of the SRE role. SREs use their coding skills to automate routine tasks, build tools, and develop scripts that enhance system reliability and efficiency. This might include writing scripts to automate deployments, developing monitoring tools, or creating solutions to address specific operational challenges.
The ability to code allows SREs to take a proactive approach to system management, creating custom solutions that are tailored to the specific needs of the organization. This skill set also enables SREs to collaborate more effectively with development teams, ensuring that new features are built with reliability in mind from the outset.
In conclusion, the role of the Site Reliability Engineer is multifaceted, requiring a blend of technical expertise, problem-solving skills, and a proactive approach to system management. SREs are vital to ensuring that modern IT systems are reliable, scalable, and capable of meeting the demands of today’s business environments.
4. SRE in Practice: Tools, Techniques, and Challenges
Site Reliability Engineering (SRE) is not just about theory; it’s about putting principles into practice to ensure that systems are reliable, scalable, and performant. SREs use a variety of tools and techniques to achieve these goals, but they also face challenges that require innovative solutions. This article explores the toolkit of an SRE, common tools used in the field, how AWS supports SRE practices, and the common pain points faced by SREs.
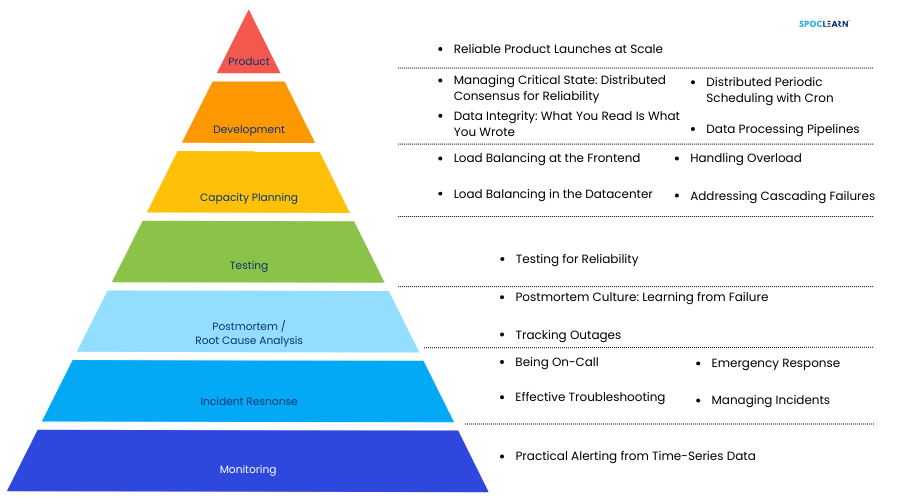
4.1 Solving for Site Reliability: An SRE’s Toolkit
An SRE’s toolkit is designed to address the core challenges of maintaining system reliability at scale. This toolkit includes a mix of automation tools, monitoring systems, incident management practices, and more. The goal is to minimize downtime, reduce manual labor, and ensure systems are resilient to failures.
Key components of an SRE’s toolkit include:
- Automation Tools: Automating routine tasks, such as deployments, scaling, and monitoring, is critical for reducing toil and improving efficiency.
- Monitoring and Alerting Systems: Continuous monitoring of systems helps in detecting issues before they escalate while alerting ensures that the right people are notified to take action.
- Incident Response Practices: Having a well-defined incident management process ensures that issues are addressed quickly and systematically, minimizing their impact on users.
- Capacity Planning Tools: These tools help in predicting and planning for future resource needs, ensuring that systems can scale without interruption.
4.2 Common SRE Tools
SREs rely on a range of tools to carry out their responsibilities effectively. Below is a table summarizing some of the most commonly used tools in SRE:
| Tool | Purpose | Examples |
|---|---|---|
| Monitoring | Continuous observation of system performance and health. | Prometheus, Nagios, Datadog |
| Alerting | Notifying teams of issues that need immediate attention. | PagerDuty, Opsgenie, VictorOps |
| Logging | Collecting and analyzing log data for troubleshooting. | ELK Stack (Elasticsearch, Logstash, Kibana), Splunk |
| Automation | Automating routine tasks to reduce manual intervention. | Jenkins, Ansible, Terraform |
| Incident Management | Coordinating response to system outages and incidents. | Jira Service Desk, ServiceNow |
| Configuration Management | Managing and maintaining system configurations. | Puppet, Chef, SaltStack |
These tools are essential for SREs to monitor systems, automate tasks, manage incidents, and ensure configurations are consistent across environments.
4.3 How AWS Supports Site Reliability Engineering
Amazon Web Services (AWS) provides a robust platform that supports SRE practices through a variety of services and tools. AWS’s cloud infrastructure is designed to be highly reliable, scalable, and secure, making it a popular choice for organizations implementing SRE.
AWS supports SRE in several ways:
- Scalability: AWS provides scalable services like EC2, S3, and Lambda, which allow SREs to scale infrastructure up or down based on demand without manual intervention.
- Monitoring and Logging: AWS offers monitoring and logging tools like CloudWatch and CloudTrail, which provide deep insights into system performance and security.
- Automation: AWS’s suite of automation tools, including CloudFormation and AWS OpsWorks, enables SREs to automate deployments, scaling, and other routine tasks.
- Incident Management: AWS provides tools for managing incidents, such as AWS Systems Manager, which helps in automating operational tasks and managing incidents effectively.
By leveraging AWS’s capabilities, SREs can build and maintain highly reliable and scalable systems with greater ease and efficiency.
4.4 Common SRE Pain Points
Despite the powerful tools and techniques available, SREs face several common challenges in their work. These pain points can affect their ability to maintain system reliability and efficiency.
- Toil: Repetitive, manual tasks that do not add long-term value can consume significant time and resources. Reducing toil is a constant challenge for SREs.
- Incident Fatigue: Frequent alerts and incidents can lead to burnout, especially if the underlying issues are not resolved. This makes it critical to prioritize and address root causes.
- Scaling Complex Systems: As systems grow in complexity, maintaining reliability becomes increasingly difficult. SREs must constantly evolve their practices to manage scale effectively.
- Balancing Innovation and Reliability: Introducing new features can introduce risks to system stability. SREs must find the right balance between supporting innovation and maintaining reliability.
Site Reliability Engineering is a practice that requires a blend of the right tools, techniques, and a proactive approach to overcoming challenges. By understanding and addressing these challenges, SREs can ensure that their systems remain reliable, scalable, and capable of supporting the needs of modern businesses.
5. SRE and DevOps: A Synergistic Relationship
In the modern IT landscape, Site Reliability Engineering (SRE) and DevOps are two practices that have revolutionized how organizations manage and deliver software. While they share common goals, such as improving system reliability and accelerating delivery, they are not the same. Understanding the relationship between SRE and DevOps is key to leveraging their strengths for optimal results. This article explores how SRE and DevOps complement each other, the differences between them, and how SRE can be seen as an implementation of DevOps principles.
5.1 SRE and DevOps: Complementary Practices
SRE and DevOps are often viewed as complementary practices, each contributing unique strengths to the overall goal of delivering reliable, scalable, and efficient software.
DevOps is a cultural and operational movement that emphasizes collaboration between development and operations teams. Its primary focus is on automating the software delivery process, reducing silos between teams, and enabling continuous delivery and integration. DevOps aims to create a seamless pipeline where code moves from development to production swiftly and securely.
SRE, on the other hand, brings a strong focus on reliability engineering to the DevOps ecosystem. It adds specific practices, such as setting service level objectives (SLOs) and managing error budgets, to ensure that systems are not only delivered quickly but also operate reliably at scale. By incorporating engineering principles into operations, SRE enhances the reliability and scalability aspects that are essential in a DevOps environment.
Together, SRE and DevOps provide a holistic approach to software development and operations. DevOps fosters a culture of collaboration and automation, while SRE ensures that the systems built and deployed through this process are robust and reliable.
5.2 DevOps vs. SRE: What’s the Difference?
While SRE and DevOps share common goals, there are key differences between the two practices.
- Focus: DevOps is broad in its approach, encompassing the entire software delivery lifecycle, from development to deployment. It aims to break down silos between teams and automate as much of the process as possible. SRE, however, has a narrower focus on ensuring system reliability and scalability. It applies software engineering techniques specifically to IT operations.
- Culture vs. Discipline: DevOps is often described as a culture or philosophy, emphasizing the importance of collaboration and automation across teams. SRE, in contrast, is more of a discipline or role within an organization, with specific responsibilities and practices centered around reliability engineering.
- Approach to Risk: DevOps focuses on reducing the risk of failure through continuous integration, testing, and deployment practices. SRE accepts that some level of risk is inevitable and manages it through concepts like error budgets and SLOs, which help balance the need for reliability with the pace of innovation.
Despite these differences, the two practices are not mutually exclusive. In fact, SRE can be seen as a specific implementation of DevOps principles, providing a framework for managing reliability within the broader DevOps approach.
Explore the key differences between SRE and DevOps in our detailed guide – SRE vs DevOps
5.3 SRE as an Implementation of DevOps Principles
SRE can be considered an implementation of DevOps principles, particularly when it comes to automating operations and ensuring continuous delivery while maintaining system reliability. By integrating software engineering practices into operations, SRE directly aligns with the DevOps emphasis on automation, collaboration, and continuous improvement.
One way SRE implements DevOps principles is through the use of automation to reduce toil. DevOps advocates for the automation of repetitive tasks to improve efficiency and reduce the potential for human error. SRE takes this a step further by systematically identifying areas of toil and developing automation solutions to address them.
Moreover, the SRE focus on monitoring, observability, and proactive incident management aligns with DevOps practices that emphasize the need for continuous feedback and improvement. SREs use these tools to ensure that systems are reliable, scalable, and capable of supporting ongoing development and deployment.
SRE and DevOps are synergistic practices that, when combined, offer a powerful approach to managing modern software systems. DevOps provides the cultural foundation and operational practices needed to accelerate delivery, while SRE adds the reliability engineering discipline necessary to ensure that these systems operate smoothly at scale. By understanding and leveraging the strengths of both practices, organizations can build and maintain robust, high-performing systems.
6. Strategic Implementation of SRE in Organizations
Site Reliability Engineering (SRE) has become a vital practice for organizations aiming to maintain high levels of reliability, scalability, and efficiency in their IT operations. Implementing SRE strategically can lead to significant improvements in service availability and overall operational excellence. This article delves into why organizations should adopt SRE, how to integrate it effectively, the keys to building a successful SRE team, and the critical role of error budgets in SRE.
6.1 Why Should You Adopt SRE?
Adopting SRE offers several compelling benefits for organizations, especially those operating in complex, high-demand environments. The primary reason to adopt SRE is its focus on reliability and scalability. In today’s digital economy, where downtime can lead to significant financial losses and damage to reputation, SRE provides a structured approach to minimizing disruptions.
SRE also introduces a proactive culture of continuous improvement. By emphasizing automation, monitoring, and the reduction of toil, SRE helps organizations operate more efficiently. This proactive stance ensures that systems are not just maintained but are constantly being refined and optimized, leading to long-term operational excellence.
Moreover, SRE’s use of engineering principles in operations helps bridge the gap between development and operations teams, fostering a more collaborative and efficient working environment. This alignment is crucial for organizations looking to accelerate their delivery pipelines while maintaining high standards of reliability.
6.2 How to Integrate SRE into Your Organization
Integrating SRE into an organization requires careful planning and a phased approach. The first step is to gain buy-in from leadership by clearly articulating the benefits of SRE and how it aligns with the organization’s strategic goals. Once leadership support is secured, the next step is to assess the current state of operations and identify areas where SRE can have the most impact.
Begin by introducing SRE practices gradually, starting with small, manageable projects. This allows teams to learn and adapt without overwhelming them. Key practices such as defining service level objectives (SLOs) and implementing error budgets should be prioritized, as they lay the foundation for the SRE approach.
It’s also essential to foster a culture of collaboration between development and operations teams. This can be achieved by organizing cross-functional teams that include both SREs and developers, ensuring that reliability is considered throughout the entire software development lifecycle.
6.3 Building and Operating an Effective SRE Team
Building an effective SRE team requires a combination of technical expertise, problem-solving skills, and a deep understanding of both development and operations. The team should consist of individuals who are not only proficient in coding and automation but also have a strong grasp of system architecture and performance engineering.
When operating an SRE team, it’s crucial to focus on continuous learning and improvement. SREs should be encouraged to stay updated on the latest tools, technologies, and best practices in reliability engineering. Regular training and knowledge-sharing sessions can help keep the team sharp and capable of tackling new challenges.
Another key aspect is ensuring that the SRE team has the right tools and resources. This includes access to monitoring, alerting, and automation tools that enable them to perform their duties effectively. Providing the team with the authority to make decisions and implement changes is also critical to their success.
6.4 Understanding Error Budgets and Their Role in SRE
Error budgets are a core concept in SRE, providing a quantifiable way to balance reliability with the pace of innovation. An error budget is essentially the allowable margin of error or downtime that a system can experience within a given period without violating the agreed-upon service level objectives (SLOs).
The role of error budgets in SRE is to manage risk and prioritize work. If a system is operating well within its error budget, the team may decide to allocate more resources to new feature development. However, if the error budget is depleted due to unexpected issues or outages, the focus shifts to improving reliability and addressing the root causes of failures.
Error budgets also facilitate better communication between development and operations teams. They provide a clear, data-driven basis for making decisions about when to prioritize reliability over new features, ensuring that all teams are aligned with the organization’s goals.
The strategic implementation of SRE can transform how an organization manages its IT operations, leading to more reliable, scalable, and efficient systems. By adopting SRE practices, building effective teams, and leveraging tools like error budgets, organizations can achieve the perfect balance between innovation and reliability, ultimately driving long-term success.
7. Industry Insights: Who’s Using SRE and How?
Site Reliability Engineering (SRE) has rapidly gained traction as organizations strive to maintain high levels of reliability and efficiency in their IT operations. Originally developed by Google, SRE has since been adopted by various leading companies worldwide. This article provides industry insights into how SRE is being used, starting with a case study of Google and exploring other organizations that have embraced this practice.
7.1 SRE at Google: A Case Study
Google is the birthplace of Site Reliability Engineering, and its implementation of SRE has set the standard for the industry. The concept was introduced by Ben Treynor Sloss, a Google engineer, who described SRE as “what happens when you ask a software engineer to design an operations team.” Google’s approach to SRE is deeply integrated into its culture, influencing how the company builds, scales, and operates its vast array of services.
At Google, SRE teams are responsible for maintaining the reliability of critical services like Search, Gmail, and YouTube. They achieve this through a combination of automation, proactive monitoring, and a unique approach to risk management. One of the key tools used by Google’s SREs is the error budget, which allows the team to balance the need for system reliability with the pace of innovation. By setting a predefined amount of acceptable risk (the error budget), Google’s SREs can make informed decisions about when to prioritize stability over new features.
Another notable aspect of Google’s SRE practice is its emphasis on postmortems. After every incident, a thorough postmortem is conducted to understand what went wrong and how similar issues can be prevented in the future. These postmortems are blameless, focusing on systemic improvements rather than individual faults. This approach has been crucial in fostering a culture of continuous improvement within the company.
Google’s success with SRE has inspired many other organizations to adopt similar practices, adapting them to their own unique environments.
7.2 Who Else is Using Site Reliability Engineering?
Beyond Google, a growing number of companies have implemented SRE to enhance their operational efficiency and service reliability. These organizations span various industries, from technology to finance and retail, each tailoring SRE principles to meet their specific needs.
- Amazon Web Services (AWS): As a leading cloud service provider, AWS relies heavily on SRE principles to ensure the reliability and scalability of its services. AWS has adopted SRE to manage its vast and complex infrastructure, focusing on automation and robust monitoring systems to maintain high availability across its global network.
- Netflix: Known for its pioneering use of cloud technologies, Netflix uses SRE to maintain the reliability of its streaming service, which operates on a massive scale. Netflix’s SRE teams focus on automating operational tasks, managing capacity, and ensuring that the service remains resilient against failures. Their approach to chaos engineering, where they deliberately introduce failures into their systems to test resilience, is a direct application of SRE principles.
- Uber: Uber’s platform operates across multiple regions with millions of users, making reliability a critical concern. Uber has implemented SRE to manage the complexities of its real-time services, such as ride-hailing and food delivery. Their SRE teams work closely with developers to ensure that new features do not compromise the system’s stability.
- Financial Institutions: Major banks and financial institutions are also adopting SRE to enhance the reliability of their digital services. For example, companies like Goldman Sachs and JPMorgan Chase use SRE to manage their online banking platforms, ensuring they can handle high transaction volumes without downtime.
These examples demonstrate that SRE is not confined to tech giants but is increasingly being adopted across various industries where reliability and scalability are paramount. Companies are recognizing that SRE offers a structured approach to managing complex systems, allowing them to deliver high-quality services consistently.
SRE has proven to be a transformative practice for organizations looking to maintain reliability while scaling their operations. From its origins at Google to its adoption by industry leaders like AWS, Netflix, and Uber, SRE is helping companies across the globe to navigate the challenges of modern IT infrastructure and deliver exceptional user experiences.
8. The Future of SRE
Site Reliability Engineering (SRE) has established itself as a crucial discipline in modern IT operations, ensuring that systems are reliable, scalable, and efficient. As technology evolves, so too does the role of SRE. This article explores the future of SRE, its relationship with cloud and cloud-native development, best practices for future-proofing your organization, and the pros and cons of being an SRE.
8.1 The Future of Site Reliability Engineering
The future of Site Reliability Engineering is likely to be shaped by the increasing complexity of IT environments and the growing demand for automation and scalability. As more organizations adopt microservices architectures and distributed systems, the role of SREs will become even more critical in managing these complex, interdependent systems.
In the coming years, we can expect SRE to expand beyond its traditional focus on reliability to include areas like security, compliance, and cost optimization. The integration of artificial intelligence (AI) and machine learning (ML) into SRE practices will also be a significant trend, enabling more predictive and proactive management of systems. AI-driven monitoring tools, for instance, can help SREs identify potential issues before they become critical, further enhancing system reliability.
Moreover, as organizations continue to embrace DevOps and continuous delivery practices, the boundaries between SRE and development will blur, with SREs playing an increasingly integrated role in the software development lifecycle.
8.2 SRE, Cloud, and Cloud-Native Development
The rise of cloud computing and cloud-native development has had a profound impact on how organizations approach SRE. Cloud environments offer the scalability and flexibility needed to support SRE practices, but they also introduce new challenges, such as managing distributed systems and ensuring service reliability across multiple regions.
SREs in cloud environments must be adept at working with cloud-native tools and technologies, such as Kubernetes for container orchestration, Prometheus for monitoring, and Terraform for infrastructure as code. These tools allow SREs to automate the deployment and management of infrastructure, ensuring that systems can scale dynamically in response to changing demands.
As cloud-native development continues to grow, the role of SREs will likely evolve to include more responsibilities related to managing cloud infrastructure and optimizing cloud costs. SREs will need to stay up-to-date with the latest cloud technologies and best practices to remain effective in these environments.
8.3 SRE Best Practices for Future-Proofing Your Organization
To future-proof your organization with SRE, it’s essential to adopt best practices that can adapt to the ever-changing technology landscape. One key practice is to invest in automation. Automating routine tasks not only reduces toil but also allows SREs to focus on more strategic activities, such as improving system reliability and optimizing performance.
Another best practice is to implement robust monitoring and observability frameworks. As systems become more complex, having deep visibility into their performance is crucial for identifying and resolving issues quickly. SREs should also prioritize continuous learning and improvement, regularly reviewing and refining their practices to keep pace with technological advancements.
Additionally, fostering a culture of collaboration between development and operations teams is vital for the success of SRE. This can be achieved by integrating SREs into development teams and encouraging shared ownership of system reliability.
8.4 Pros and Cons of Being a Site Reliability Engineer
Being an SRE comes with its own set of advantages and challenges. On the positive side, SREs are in high demand, with organizations recognizing the critical role they play in maintaining system reliability. This demand often translates into competitive salaries and opportunities for career growth. SREs also enjoy the satisfaction of solving complex problems and having a tangible impact on the organization’s success.
However, the role can also be demanding and stressful. SREs are often on the front lines during incidents, responsible for quickly diagnosing and resolving issues. The pressure to maintain high levels of reliability in complex systems can lead to burnout if not managed properly. Additionally, the need to stay current with rapidly evolving technologies can be both challenging and time-consuming.
| Pros of Being an SRE | Cons of Being an SRE |
|---|---|
| High demand and competitive salaries | High-pressure role with responsibility for reliability |
| Opportunities for career growth and advancement | Risk of burnout due to incident management |
| Satisfaction from solving complex problems | Need for continuous learning and skill development |
| Tangible impact on organization’s success | Requires balancing innovation with reliability |
The future of SRE is bright, with the role evolving to meet the demands of increasingly complex and dynamic IT environments. By embracing best practices and staying ahead of technological trends, SREs can continue to play a vital role in ensuring the reliability and success of their organizations. However, it’s important to be mindful of the challenges and find ways to manage them effectively.
9. SRE Career Insights
A career in Site Reliability Engineering (SRE) offers a unique blend of challenges and opportunities, making it an appealing choice for those who enjoy solving complex problems and working at the intersection of software development and IT operations. As organizations increasingly rely on technology, the demand for skilled SREs continues to grow. This article provides insights into the essential skills needed to succeed as an SRE and an overview of what you can expect in terms of salary.
9.1 Essential Skills for a Successful SRE
To excel as a Site Reliability Engineer, a combination of technical skills, problem-solving abilities, and a deep understanding of both software development and IT operations is crucial. Here are some of the essential skills that contribute to a successful SRE career:
- Coding and Scripting: SREs often need to write code to automate tasks, manage infrastructure, and develop tools that enhance system reliability. Proficiency in languages like Python, Go, or Shell scripting is essential. Additionally, knowledge of infrastructure as code (IaC) tools like Terraform or Ansible can be highly beneficial.
- Systems Architecture: Understanding how systems are designed and how different components interact is vital for maintaining reliability. SREs need to be familiar with distributed systems, cloud architecture, microservices, and containerization technologies such as Docker and Kubernetes.
- Monitoring and Observability: SREs must be skilled in setting up and using monitoring tools to track system performance and detect issues. Familiarity with tools like Prometheus, Grafana, and ELK Stack (Elasticsearch, Logstash, Kibana) is often required. Observability extends this by providing deeper insights into system behavior, which helps in diagnosing and preventing problems.
- Incident Management: Being able to respond quickly and effectively to system failures is a core responsibility of an SRE. This includes not only fixing issues as they arise but also conducting postmortems to prevent future occurrences. Strong problem-solving skills and the ability to stay calm under pressure are critical.
- Collaboration and Communication: SREs work closely with development and operations teams, so effective communication and collaboration skills are essential. The ability to convey complex technical concepts to non-technical stakeholders is also important.
- Security Awareness: As security becomes increasingly important, SREs must understand basic security principles and how to implement them within their systems. This includes knowledge of best practices for securing infrastructure, handling data securely, and managing access controls.
- Continuous Learning: The field of SRE is constantly evolving, with new tools, technologies, and best practices emerging regularly. A commitment to continuous learning and professional development is key to staying ahead in this dynamic field.
9.2 SRE Salaries: What You Need to Know
Salaries for Site Reliability Engineers are generally competitive, reflecting the high demand and specialized skill set required for the role. Several factors influence SRE salaries, including experience, location, and the size of the organization.
- Experience Level: Entry-level SREs can expect to earn a lower salary compared to their more experienced counterparts. However, even at the entry-level, SRE salaries are typically higher than those for other IT roles. As SREs gain experience and take on more complex responsibilities, their earning potential increases significantly.
- Location: Geographical location plays a significant role in determining SRE salaries. In regions with a high cost of living, such as San Francisco, New York, or London, SREs can expect to earn higher salaries. Conversely, salaries may be lower in regions with a lower cost of living, though remote work opportunities can sometimes offset these differences.
- Industry and Company Size: The industry in which an SRE works can also impact salary. For example, SREs in the tech industry, particularly at large, well-funded companies like Google, Amazon, or Netflix, tend to earn more than those in other sectors. Similarly, larger organizations with complex IT environments may offer higher salaries to attract top talent.
Here is a general overview of SRE salary ranges based on experience and location:
| Experience Level | Low Cost of Living Area | High Cost of Living Area | Top Tech Companies |
|---|---|---|---|
| Entry-Level | $80,000 – $100,000 | $110,000 – $130,000 | $120,000 – $140,000 |
| Mid-Level | $100,000 – $120,000 | $130,000 – $150,000 | $150,000 – $170,000 |
| Senior-Level | $120,000 – $140,000 | $150,000 – $180,000 | $180,000 – $200,000+ |
A career in SRE offers both financial rewards and the opportunity to work on challenging, impactful projects. By developing the essential skills required for the role and staying informed about industry trends, SREs can build successful, long-term careers in this growing field.
10. Conclusion
As technology continues to evolve and organizations rely more heavily on digital infrastructure, the importance of Site Reliability Engineering (SRE) cannot be overstated. Embracing SRE offers numerous benefits that go beyond just maintaining system uptime; it fosters a culture of continuous improvement, innovation, and collaboration. In this conclusion, we will explore the benefits of adopting SRE and summarize the key takeaways that organizations should consider when implementing SRE practices.
10.1 The Benefits of Embracing SRE
Adopting SRE provides a structured approach to managing the reliability and scalability of complex systems, offering several significant benefits:
- Improved System Reliability: At its core, SRE is about ensuring that systems are reliable and can handle the demands placed upon them. By focusing on automation, monitoring, and proactive incident management, SRE helps reduce downtime and ensures that systems remain available when users need them.
- Scalability and Efficiency: SRE practices are designed to help organizations scale their infrastructure efficiently. Through the use of automation and infrastructure as code (IaC), SREs can manage large, distributed systems with ease, ensuring that resources are used effectively and that systems can grow without compromising performance.
- Cost Optimization: By implementing error budgets and focusing on service level objectives (SLOs), SREs help organizations strike a balance between innovation and reliability. This balance often leads to cost savings, as resources are allocated more effectively, and systems are optimized to meet performance goals without over-provisioning.
- Enhanced Collaboration: SRE fosters a culture of collaboration between development and operations teams. This cross-functional approach ensures that reliability is built into the software from the ground up, reducing the friction between teams and leading to more seamless deployments.
- Continuous Improvement: SRE is not a one-time implementation but a continuous process of refinement. By conducting blameless postmortems and using data-driven insights, SREs continuously improve systems, processes, and practices, leading to a more resilient and adaptive organization.
10.2 Summarizing the Key Takeaways from SRE
As we conclude our exploration of Site Reliability Engineering, it’s important to summarize the key takeaways that organizations should keep in mind when considering the adoption of SRE:
- SRE is a Discipline, Not Just a Role: While SREs are often specific individuals or teams within an organization, the principles of SRE should be embraced across the entire organization. This means integrating reliability engineering practices into the software development lifecycle and making reliability a shared responsibility.
- Automation is Key: One of the fundamental principles of SRE is reducing toil through automation. By automating repetitive tasks, SREs can focus on higher-value activities that improve system reliability and efficiency. Automation also reduces the potential for human error, leading to more consistent and reliable outcomes.
- Error Budgets Help Balance Risk and Innovation: Error budgets are a critical tool in SRE, allowing organizations to manage the trade-off between reliability and the need for rapid innovation. By setting clear expectations around acceptable levels of risk, organizations can make informed decisions about when to prioritize new features and when to focus on stability.
- Monitoring and Observability Are Essential: To effectively manage reliability, organizations must have deep visibility into their systems. Monitoring and observability provide the data needed to detect issues early, understand system behavior, and make informed decisions about where to focus resources.
- Continuous Learning and Improvement: SRE is a dynamic field that requires a commitment to continuous learning and improvement. Organizations that embrace this mindset are better equipped to adapt to changes in technology and user demands, ensuring long-term success.
Site Reliability Engineering offers a powerful framework for managing the complexities of modern IT environments. By embracing SRE practices, organizations can achieve higher levels of reliability, scalability, and efficiency, ultimately driving better outcomes for their business and their customers. As the digital landscape continues to evolve, the principles of SRE will remain a cornerstone of successful IT operations.
© 2022 spoclearn.com