


Site Reliability Engineering (SRE) has emerged as a transformative approach for improving the reliability, scalability, and overall performance of systems in organizations that demand continuous and highly available services. Initially developed at Google in the early 2000s, SRE bridges the gap between development and operations teams by applying software engineering practices to IT operations problems.
This blog will explore the core concepts of SRE, its evolution, how it differs from traditional IT roles, and why it’s essential in today’s fast-paced digital environment.
The Evolution of SRE
The inception of SRE is closely linked to Google, where it was introduced to address the challenges of managing large-scale systems. Google aimed to achieve both reliability and rapid feature development, balancing the demands of software development with the need for reliable services.
In the early 2000s, as web applications became more complex and user expectations grew, the traditional operations teams struggled to keep up with the requirements of continuous availability and rapid deployment cycles. SRE was introduced to solve these problems by bringing a software engineering mindset to system operations. It was spearheaded by Ben Treynor Sloss, a Google engineer, who famously said, “SRE is what happens when you ask a software engineer to design an operations function.”
Read More: The Evolution of Site Reliability Engineering: A Comprehensive Guide
Core Principles of Site Reliability Engineering
SRE is built on a set of principles that focus on improving the operational efficiency of systems while maintaining a balance between development speed and system reliability. Below are some of the key principles:
1. Service Level Objectives (SLOs) and Service Level Indicators (SLIs)
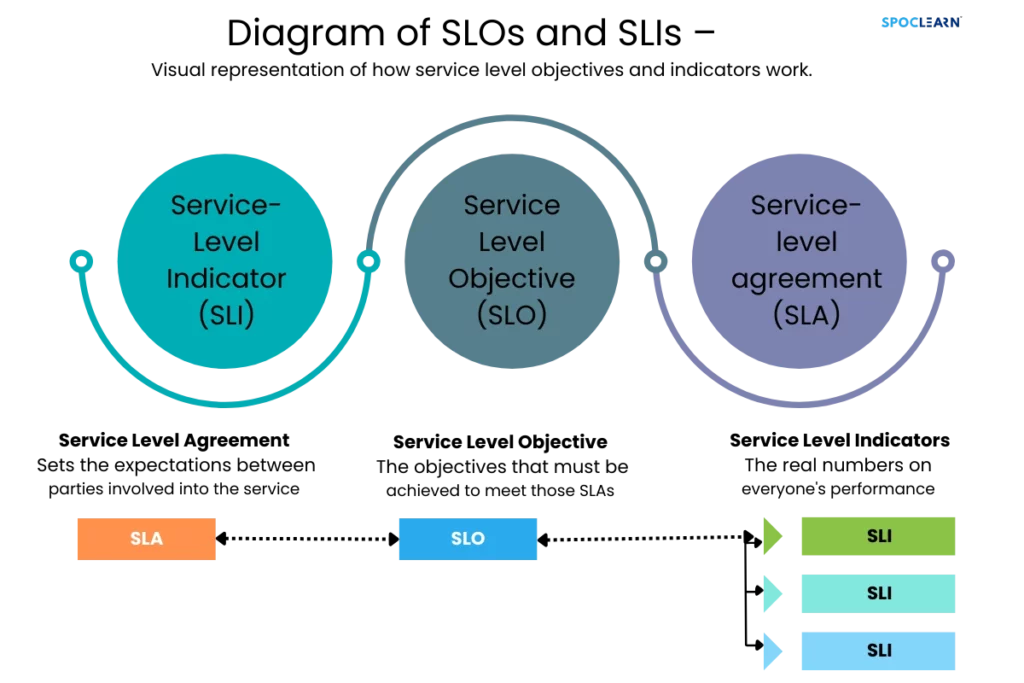
SLOs are agreed-upon standards that define the acceptable performance of a system, while SLIs are the metrics used to measure the system’s performance against those standards. These are foundational to SRE because they help teams set measurable goals for system reliability.
For example, an SLO might specify that a system should be available 99.9% of the time, while an SLI would track the actual uptime to ensure the system meets this goal.
2. Error Budgets
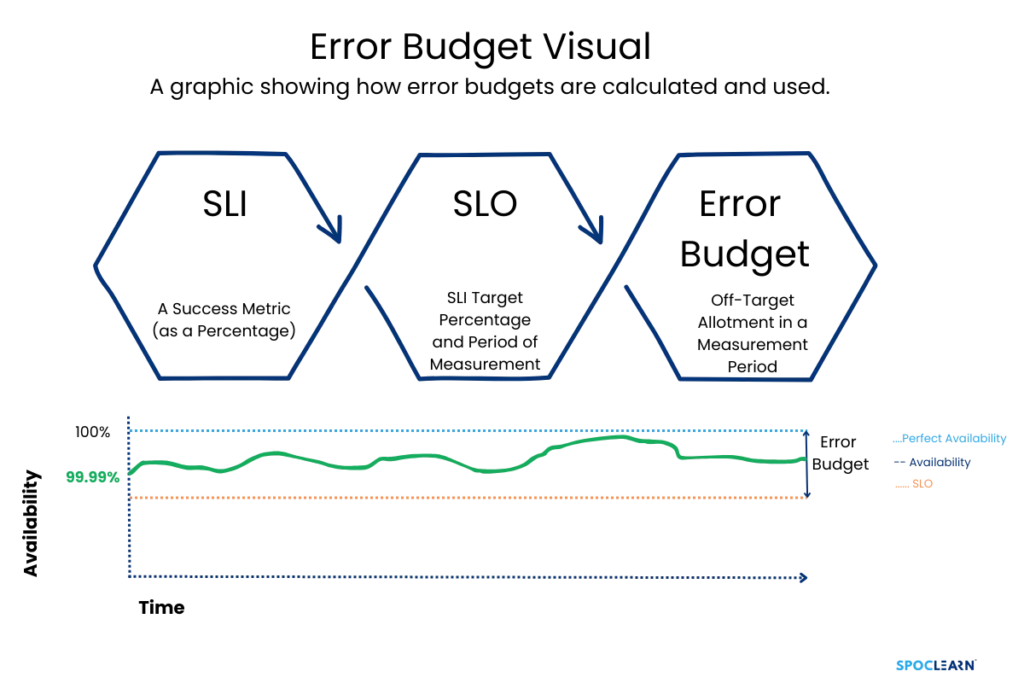
Error budgets provide a way to balance reliability and innovation. Instead of striving for 100% uptime (which is costly and often unnecessary), SRE allows for a defined amount of downtime (the error budget) to encourage risk-taking and faster development cycles. The error budget is calculated as the difference between the target reliability (SLO) and 100%. If the system fails too often and exceeds the error budget, development slows down to focus on reliability improvements.
3. Automation to Reduce Toil
Toil refers to repetitive, manual tasks that do not provide long-term value. SRE’s core philosophy is to automate as much of this toil as possible. By automating tasks like deployments, monitoring, and scaling, SRE teams free up time to focus on more complex and valuable work.
4. Blameless Postmortems
A crucial cultural aspect of SRE is conducting blameless postmortems after incidents. This practice ensures that teams focus on solving problems and learning from failures rather than assigning blame to individuals. This approach fosters a culture of transparency and continuous improvement.
5. Monitoring and Observability
SRE emphasizes the importance of proactive monitoring and observability. Teams implement comprehensive monitoring to gain insight into system performance, identify potential issues early, and take corrective actions before they impact users. Observability tools help engineers understand system behaviors and troubleshoot issues more effectively.
Read More: Site Reliability Engineering (SRE): Core Principles Explained
SRE vs. DevOps: What’s the Difference?
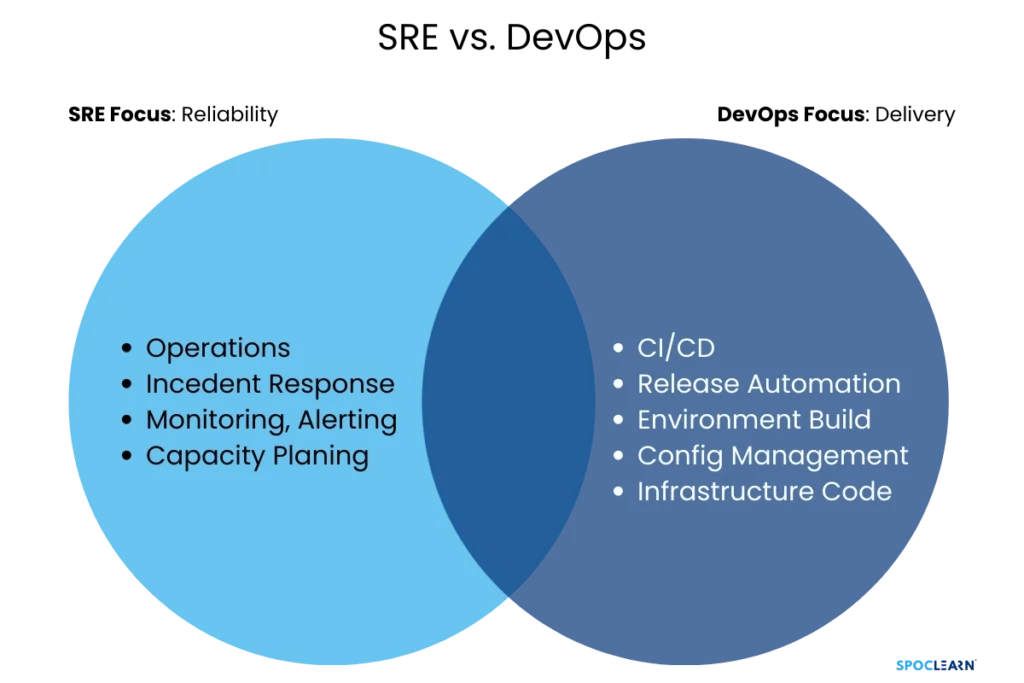
Although SRE and DevOps are often compared or even confused, they are distinct approaches with different focuses.
- DevOps emphasizes collaboration between development and operations teams to improve software delivery speed and operational stability. It encourages practices like continuous integration (CI) and continuous delivery (CD) to streamline the development lifecycle.
- SRE, on the other hand, is a specific implementation of DevOps principles, with a strong focus on system reliability and automation. It introduces engineering rigor to operations tasks, with a focus on metrics, error budgets, and reducing manual work.
While DevOps is more of a cultural movement, SRE applies software engineering principles to operations and is more structured around reliability.
Why SRE is Essential in Modern IT
SRE has become essential for organizations that operate large-scale, complex systems, where continuous availability and high performance are critical. Below are some reasons why SRE is vital in modern IT environments:
1. Scalability
As organizations scale their operations, managing systems manually becomes impractical. SRE introduces automation and scalable processes that enable organizations to grow without sacrificing reliability.
2. Balancing Innovation with Reliability
By using error budgets and other SRE practices, teams can innovate and deploy new features faster while maintaining system reliability. This balance is crucial in industries where customer expectations for uptime and performance are extremely high.
3. Reducing Operational Costs
Automating repetitive tasks and minimizing toil leads to more efficient operations. SRE practices reduce the need for manual intervention, which in turn lowers operational costs and allows engineers to focus on high-impact projects.
4. Proactive Incident Management
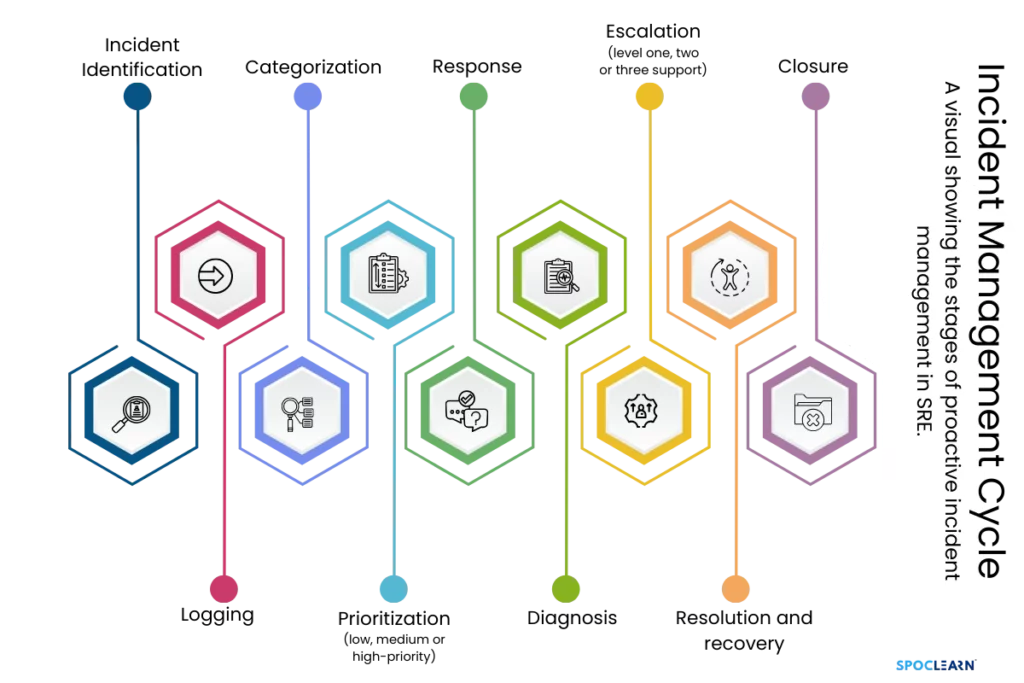
With SRE’s focus on monitoring, observability, and blameless postmortems, organizations can prevent issues before they escalate. SRE teams are equipped to identify performance bottlenecks, troubleshoot failures, and resolve incidents faster, ensuring minimal impact on users.
5. Continuous Improvement
SRE emphasizes continuous learning and improvement. The blameless postmortem process, combined with regular monitoring, allows teams to learn from their mistakes, identify systemic issues, and improve their operational practices over time.
SRE Tools and Technologies
Several tools are integral to the successful implementation of SRE. These tools help teams monitor systems, automate tasks, and manage incident responses:
- Monitoring Tools: Prometheus, Grafana, Datadog, and ELK Stack (Elasticsearch, Logstash, and Kibana) are popular tools for tracking system metrics and visualizing performance.
- Automation Tools: Terraform, Ansible, and Chef are used to automate infrastructure management and reduce toil.
- Incident Response Tools: PagerDuty and OpsGenie are commonly used for alerting and incident management. These tools ensure that teams can respond quickly to system failures.
- CI/CD Pipelines: Jenkins, CircleCI, and TravisCI automate the process of integrating and deploying code, ensuring that new features are rolled out smoothly.
Case Study: SRE at Google
Google, where SRE was born, is a prime example of its success. The company operates thousands of services with minimal downtime. By following SRE principles such as error budgets and proactive monitoring, Google has been able to ensure the reliability of its services, such as Gmail, Google Search, and YouTube, while continuously deploying new features.
Google’s approach to SRE has since been adopted by other tech giants, including Amazon, Netflix, and Facebook, showcasing the broad applicability and success of SRE in the tech industry.
The Future of SRE
As organizations continue to embrace digital transformation, the demand for SRE is expected to grow. Several trends are shaping the future of SRE:
- Artificial Intelligence and Machine Learning: AI and ML will play a larger role in SRE, enabling predictive maintenance and automated incident responses.
- Edge Computing: The rise of edge computing will introduce new challenges for reliability, and SRE practices will need to adapt to ensure consistent performance across distributed environments.
- DevSecOps Integration: SRE will increasingly integrate with security practices (DevSecOps), making security a fundamental part of system reliability.
Conclusion
Site Reliability Engineering (SRE) represents a paradigm shift in how organizations manage operations and maintain system reliability. By applying software engineering principles to IT operations, SRE enables teams to build more reliable, scalable, and efficient systems. Its principles of error budgets, automation, and blameless postmortems have made it a critical practice for modern organizations looking to balance innovation with reliability.
